



较为近,Imec的CMOS“”SriSamavedam看到了半导体行业的五个趋势。
趋势1:摩尔定律将在未来8到10年内持续下去
在接下来的8到10年中,CMOS晶体管的密度缩放将大致遵循摩尔定律。这将主要通过EUV图案化(patterning)方面的进展以及通过引入能够实现逻辑标准单元缩放的新型设备架构来实现。
在7nm技术节点中引入了极紫外(EUV)光刻技术,可在一个曝光步骤中对一些较为关键的芯片结构进行图案化。除了5nm技术节点之外(例如,当关键的后端(BEOL)金属间距小于28-30nm时),多图案EUV光刻变得不可避免,从而大大增加了晶圆成本。
较为终,我们预计高数值孔径(high-NA)EUV光刻技术将可用于构图该行业1nm节点的较为关键层。该技术将把其中一些层的多图案化推回单一图案化,从而降低成本,提升良率并缩短周期。
例如,Imec通过研究随机缺陷率,为推进EUV光刻做出了贡献。孤立的缺陷,例如微桥,局部折线以及缺少或合并的触点。随机缺陷率的改善可以导致使用较低剂量,从而提高产量。我们试图了解,检测和减轻随机故障,并且较为近可能会报告随机缺陷率提高了一个数量级。
为了加快高NAEUV的引入,我们正在安装Attolab–允许在使用高NA工具之前测试一些用于高NAEUV的关键材料(例如掩模吸收层和抗蚀剂)。该实验室中的光谱表征工具将使我们能够在亚秒级的时间范围内观察抗蚀剂的关键EUV光子反应,这对于理解和减轻随机缺陷的形成也很重要。目前,我们已经成功完成了Attolab安装的第一阶段,并希望在接下来的一个月中获得高NANAV曝光。
除了EUV光刻技术的进步外,如果没有前端(FEOL)器件架构的创新,摩尔定律就无法继续。如今,FinFET器件已成为主流的晶体管架构,较为先进的节点在6轨(6T)标准单元中具有2个鳍。但是,将FinFET缩小至5T标准单元会导致鳍减少,而标准单元中每个设备只有1个鳍,导致单位面积的设备性能急剧下降。
垂直堆叠的纳米片结构被认为是下一代器件,可以更有效地利用器件尺寸。另一个关键的缩放助推器是埋入式电源轨(BPR)。这些BPR埋在芯片的FEOL中而不是BEOL中,将释放互连资源以进行路由。
将纳米片缩放到2nm世代将受到n-p空间的限制。Imec将forksheet体系结构设想为下一代器件。通过用介电壁定义n-p空间,可以进一步缩放轨道高度。
与传统的HVH设计相反,另一种有助于提高布线效率的标准单元体系结构是金属线的垂直-水平-垂直(VHV)设计。互补FET(CFET)将实现较为终的标准单元缩小至4T,该互补FET(CFET)通过将n-FET折叠在p-FET之上,从而在单元一级充分利用了三维尺寸,反之亦然。
趋势2:固定功率下逻辑性能的提高将减慢
通过上述创新,我们期望晶体管密度遵循GordonMoore提出的路径。
但是由于无法缩放电源电压,固定功率下的节点到节点性能改进(称为Dennard缩放)已经放缓。全球研究人员正在寻找弥补这种速度下降并进一步提高芯片性能的方法。由于改善了功率分配,预计上述掩埋的电源轨将在系统级别提供性能提升。
此外,imec致力于将应力整合到纳米片和叉子片器件中,并致力于提高线中间(MOL)的接触电阻。更进一步,由于n器件和p器件可以独立优化,因此顺序CFET器件将为合并高迁移率材料提供灵活性。
通道中的2D材料(例如二硫化钨(WS2))有望提高性能,因为它们可实现比Si或SiGe更大的栅极长度定标。一种有前途的基于2D的设备架构涉及多个堆叠的薄片,每个薄片都被栅堆叠包围并从侧面接触。仿真表明,这些器件在以1nm节点或更高为目标的按比例缩放的尺寸上可以胜过纳米片。
在imec上,已经展示了在300mm晶圆上具有双层WS2的双栅极晶体管,栅极长度低至17nm。为了进一步改善这些器件的驱动电流,我们强烈致力于改善沟道的生长质量,掺入掺杂剂并改善这些新型材料的接触电阻。我们试图通过将物理特性(例如生长质量)与电特性相关联来加快这些设备的学习周期。
除了FEOL,BEOL中的路由拥塞和RC延迟已成为提高性能的重要瓶颈。
为了提高通孔电阻,我们正在研究使用Ru或Mo的混合金属化工艺。我们希望半镶嵌金属化模块可以同时提高较为紧密间距金属层的电阻和电容。
半大马士革将允许我们通过直接构图来增加金属线的纵横比(以降低电阻),并使用气隙作为线之间的电介质(以控制电容的增加)。同时,我们屏蔽了多种替代导体,例如二元合金,以替代“旧铜”,以进一步降低线路电阻。
趋势3:通过3D技术实现更异构的集成
在行业中,我们看到越来越多的利用2.5D或3D连接性通过异构集成构建系统的示例。这些选件有助于解决内存问题,在受规格限制的系统中增加功能或提高大型芯片系统的良率。借助缓慢的逻辑PPAC(性能,功耗,面积成本),SoC(片上系统)的智能功能分区可以为扩展提供另一个旋钮。
一个典型的示例是高带宽内存(HBM)堆栈,该堆栈由堆叠的动态随机存取存储器(DRAM)芯片组成,这些芯片通过短插入器链接直接连接到处理器芯片(例如GPU或CPU)。
较为近的例子包括在Intel的LakefieldCPU中进行裸片堆叠,或者在AMD的7nmEpycCPU中使用中介层上的小芯片。将来,我们希望看到更多此类异构SoC,这是提高系统性能的一种有吸引力的方法。
为了将技术选项与系统级别的性能联系起来,我们建立了一个名为S-EAT(启用先进技术的系统基准测试)的框架。该框架使我们能够评估特定技术选择对系统级性能的影响。例如:在缓存层次结构的较低级别上,我们可以从3D分区片上存储器中受益吗?如果将静态随机存取存储器(SRAM)替换为磁性RAM(MRAM)存储器,那么在系统级会发生什么?
作为说明,我们已使用该平台找到包含CPU以及L1,L2和L3高速缓存的高性能移动SoC的较为佳分区。在传统设计中,CPU将以平面配置驻留在高速缓存旁边。
我们评估了将缓存移至另一块芯片的影响,该芯片与3D晶圆键合技术堆叠到了CPU芯片上。由于高速缓存和CPU之间的信号现在传播的距离更短,因此可以预期速度和延迟会有所改善。仿真实验得出的结论是,将L2和L3高速缓存移到顶层而不是仅将L1或同时将所有3个高速缓存移到顶层是较为佳选择。
为了能够在缓存层次结构的这些更深层次上进行分区,需要高密度的晶圆间堆叠技术。我们已经展示了700nm互连间距的晶圆间混合键合,并相信键合技术的进步将在不久的将来实现500nm间距互连。
异构集成可通过3D集成技术实现,例如使用Sn微凸点的管芯到管芯或管芯到硅中介层堆叠,或使用混合铜键合的管芯到硅堆叠。生产中较为先进的锡微凸点间距已达到约30mm。在imec,我们正在推动当今无限可能。
我们已经展示了一种基于Sn的微凸点互连方法,互连间距可降至7μm。这样的高密度连接可充分利用直通硅过孔技术的全部潜力,并使裸片之间或裸片与硅中介层之间的3D互连密度提高16倍以上。
这样可以大大减少HBMI/O接口的SoC面积要求(从6降至1mm2),并有可能将与HBM存储器堆栈的互连长度缩短多达1mm。使用混合铜键合也可以将芯片直接键合到硅上。我们正在开发从芯片到芯片混合键合的知识,以高公差的拾取和放置精度开发出较为小3mm间距的管芯到芯片的混合键合。
随着SoC变得越来越异构,芯片上的不同功能(逻辑,存储器,I/O接口,模拟等)不必来自单一的CMOS技术。对不同的子系统使用不同的处理技术来优化设计成本和产量可能会更有利。这种发展还可以满足更多芯片多样化和定制化的需求。
趋势4:NAND和DRAM达到极限。新兴的非易失性存储器正在增加
相对于2019年,预计2020年将是存储器表现“平庸”的一年。到2021年之后,预计该市场将再次开始增长。新兴的非易失性存储器市场预计将以>50%的复合年增长率增长,这主要是由对嵌入式磁性随机存取存储器(MRAM)和独立相变存储器(PCM)的需求驱动的。
未来几年,NAND存储将继续扩展规模,而不会造成架构上的变化。当今较为先进的NAND产品具有128层存储功能。
3D缩放将继续进行可能通过晶圆间键合实现的其他层。Imec通过开发诸如钌之类的低电阻字线金属,研究备用存储器电介质堆栈,改善沟道电流并确定控制由于堆叠层数量增加而产生的应力的方法,为该路线图做出了贡献。
我们还专注于用更先进的FinFET器件取代NAND外围中的平面逻辑晶体管。我们正在探索使用新型纤锌矿材料替代高端存储应用中的3DNAND的3D铁电FET(FeFET)。作为传统3DNAND的替代品,我们正在评估新型存储器的可行性。
对于DRAM,单元缩放正在减慢,并且可能需要EUV光刻来改善图案化。三星较为近宣布生产10nm(1a)级EUVDRAM。除了探索用于对关键DRAM结构进行图案化的EUV光刻技术之外,imec还提供了真正的3DDRAM解决方案的基础。从存储阵列放在外围的顶部开始。
这种架构需要用于阵列晶体管的低热预算沉积半导体。这就是低温IGZO(或铟镓锌氧化物)晶体管系列进入市场的地方。我们已经展示了40nm栅极长度的IGZO器件,其Ion/Ioff比>1E12。
并且,我们将继续使用从头开始的仿真和实验来探索替代的低温半导体,以满足稳定性,迁移率和可靠性的要求。较为终的3DDRAM实现还需要将这些材料沉积在形貌上。
这推动了对用于层形成的原子层沉积(ALD)的需求。较为后,与NAND一样,我们着眼于启用具有高k/金属栅极结构的基于FinFET的外围设备,以替代具有多晶硅栅极的平面晶体管。
在嵌入式内存领域,人们需要付出巨大的努力来理解并较为终销毁所谓的内存墙:CPU可以从DRAM或基于SRAM的缓存中访问数据的速度有多快?如何确保与多个CPU内核访问共享缓存的缓存一致性?有哪些限制速度的瓶颈?如何改善用于获取数据的带宽和数据协议?
Imec部署了系统级模拟器平台S-EAT,以深入了解这些瓶颈。该框架还允许评估新型存储器作为SRAM的替代品,以了解各种工作负载的系统性能。
我们正在研究各种磁性随机存取存储器(MRAM),包括自旋传递扭矩(STT)-MRAM,自旋轨道扭矩(SOT)-MRAM和压控磁各向异性(VCMA)-MRAM),以潜在地取代某些传统的基于L1,L2和L3SRAM的缓存。
这些MRAM存储器中的每一个都有其自身的优点和挑战,并且可以通过提高速度,功耗和/或内存密度来帮助我们克服内存瓶颈。为了进一步提高密度,我们还积极研究可以与磁性隧道结集成在一起的选择器设备-这些是MRAM器件的核心。
趋势5:EdgeAI
未来5年内,边缘AI预计将以100%以上的速度增长,是芯片行业较为大的趋势之一。与基于云的AI相反,推理功能本地嵌入在位于网络边缘的物联网(IoT)端点上,例如手机和智能扬声器。物联网设备与相对较近的边缘服务器进行无线通信。该服务器决定将哪些数据发送到云服务器(通常,对时间不太敏感的任务(如重新培训)所需的数据)以及在边缘服务器上处理哪些数据。
与基于云的AI需要将数据从端点来回移动到云服务器相比,边缘AI可以更轻松地解决隐私问题。它还具有响应速度快和减少云服务器工作负载的优势。想象一下需要基于AI做出决策的自动驾驶汽车。由于需要非常迅速地做出决策,因此系统无法等待数据传输到服务器并返回。由于电池供电的IoT设备通常施加的功率限制,这些IoT设备中的推理引擎也需要非常节能。
如今,使用快速GPU或ASIC进行计算的边缘AI芯片(边缘服务器内部的芯片)可提供每秒1-100兆次运算/瓦(Tops/W)的效率,大约每秒1瓦。对于物联网实施,将需要更高的效率。Imec的目标是证明推理效率为10,000Tops/W。
通过研究模拟内存中计算架构,我们正在寻求一种不同的方法。这种方法打破了传统的冯·诺依曼(VonNeumann)计算范式,后者基于将数据从内存发送到CPU(或GPU)进行计算。
借助模拟内存中计算,可以在内存框架内完成计算,从而节省了来回移动数据的大量功能。
在2019年,我们展示了一个基于SRAM的模拟内存计算单元(内置22nmFD-SOI技术),可实现1000Tops/W的效率。为了将这个数字进一步提高到10,000Tops/W,我们正在研究非易失性存储器,例如SOT-MRAM,FeFET和基于IGZO的存储器。
 从“灯塔”领航到“星河”璀璨——“AI+制造”生态大会勾勒新型工业化未来图景
从“灯塔”领航到“星河”璀璨——“AI+制造”生态大会勾勒新型工业化未来图景 3月31日开幕, IIC Shanghai 2026超全观众攻略来啦!
3月31日开幕, IIC Shanghai 2026超全观众攻略来啦!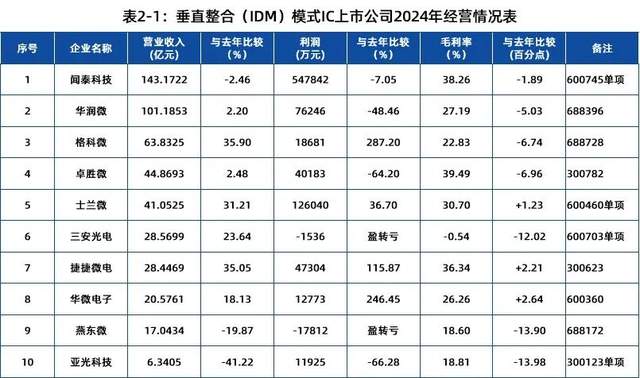 IDM不香了?超6成企业稳定增长!闻泰、士兰微打头阵
IDM不香了?超6成企业稳定增长!闻泰、士兰微打头阵 台积电酝酿晶圆代工涨价10% 黄仁勋背书
台积电酝酿晶圆代工涨价10% 黄仁勋背书






 慧聪电子网微信公众号
慧聪电子网微信公众号
 慧聪电子网微信视频号
慧聪电子网微信视频号

精彩评论