



导读:CPU缓存与内存延迟测试,相信大家都有所耳闻,但是GPU同样的测试却几乎没人做过。
CPU缓存与内存延迟测试,相信大家都有所耳闻,但是GPU同样的测试却几乎没人做过。
ChipsAndCheese就做了一次特别的测试,对比考察了AMD、NVIDIAGPU架构的缓存、显存迟问题。
首先是AMDRDNA2、NVIDIAAmpere两家最新架构的比拼,代表是RX6900XT、RTX3090,前者在几乎所有阶段都完胜。
RNDA2架构创新性地加入了InfinityCache无限缓存,提升带宽的同时,延迟也可圈可点,二级缓存命中率上只增加了大约20ns的延迟,明显低于Ampere。
更惊人的是,RDNA2显存延迟和Ampere几乎一模一样,但是别忘了,Ampere只有两个层级的缓存,RDNA2却有四个。
Ampere的缓存架构更加传统,SM阵列私有一级缓存到二级缓存要增加超过100ns的延迟,RDNA2从零级缓存到二级缓存则只增加了约66ns。看起来,GA102核心面积过大,也直接增加了延迟。
这正好可以解释AMDRDNA2架构在低分辨率下性能、能效更优秀,因为二级缓存、三级缓存延迟很低,更适合执行较小的负载。Ampere则相反,高负载下优势明显,比如说4K分辨率。
说完了GPU之间的对比,那么GPU、CPU放在一起怎么样呢?这里以RX6900XT、Intel四代酷睿i7-4770为例来看看。
CPU的缓存自然不是一个级别的,所以这里Y轴用了线性数据,可以看到全程大大低于RDNA2,搭配DDR3-1600CL9内存延迟只有63ns,RX6900XT、GDDR6的组合则有226ns,另外末级缓存平均延迟分别是53.42ns、123.2ns。
再看看前几代的NVIDIAGPU,包括Maxwell架构的GTX980Ti、Pascal架构的GTX1080、Turing架构的RTX2060Mobile。
Maxwell、Pascal其实差不多,前者整体略高一些,可能是受制于芯片面积较大、核心频率较低。
Turing则已经有了Ampere的样子,一级缓存延迟低得多,二级差不多,奇怪的是显存延迟在32MB之后偏高,原因未知。
AMD考察了TeraScale架构的HD5850/6950、GCN架构的HD7970,再加上RX6900XT,很明显在逐代降低,而且是各级缓存都在同时进步。
 从“灯塔”领航到“星河”璀璨——“AI+制造”生态大会勾勒新型工业化未来图景
从“灯塔”领航到“星河”璀璨——“AI+制造”生态大会勾勒新型工业化未来图景 3月31日开幕, IIC Shanghai 2026超全观众攻略来啦!
3月31日开幕, IIC Shanghai 2026超全观众攻略来啦!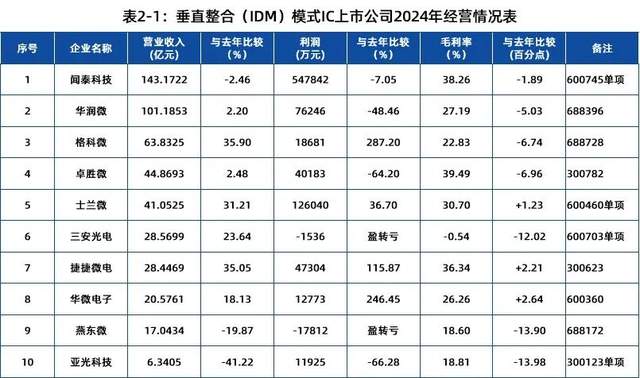 IDM不香了?超6成企业稳定增长!闻泰、士兰微打头阵
IDM不香了?超6成企业稳定增长!闻泰、士兰微打头阵 台积电酝酿晶圆代工涨价10% 黄仁勋背书
台积电酝酿晶圆代工涨价10% 黄仁勋背书






 慧聪电子网微信公众号
慧聪电子网微信公众号
 慧聪电子网微信视频号
慧聪电子网微信视频号

精彩评论