



近年来,越来越多关于⽹络压缩和加速的⽅法被提出,它们从不同的角度去实现⽹络的压缩和加速,比如量化。
深度学习已成为许多机器学习应⽤程序不可或缺的⼀部分,现在可以在⽆数电⼦设备和服务中找到,从智能⼿机和家⽤电器到⽆⼈机、机器⼈和⾃动驾驶汽车。随着深度学习在我们⽇常⽣活中的普及,对快速且节能的神经⽹络推理的需求也在增加。神经⽹络量化是降低推理过程中神经⽹络的能量和延迟要求的最有效⽅法之⼀。
包括英伟达、⾼通、华为、AMD在内的⼚家,都在神经⽹络加速⽅⾯投⼊了研发⼒量。通过量化、裁剪和压缩来降低模型尺⼨。更快的推断可以通过在降低精度的前提下使⽤⾼效计算平台⽽达到,其中包括intel MKL-DNN,ARM CMSIS,Qualcomm SNPE,Nvidia TensorRT。
⼈⼯智能⼀直是⼀个备受关注的热点研究领域。到⽬前,以深度神经⽹络(deep neural networks,DNN)为代表的联结主义⽅法成为了⼈⼯智能领域的研究热点。作为深度神经⽹络中应⽤最为⼴泛的类型,卷积神经⽹络已经在计算机视觉、语⾳分析、⾃然语⾔处理等各类任务中取得了许多突破性的成果。2012年,AlexNet以⾼于第⼆名近11%的分类精度的成绩取得ImageNet ILSVRC 2012⽐赛的冠军,引爆了深度卷积神经⽹络的研究热潮。随后,各类卷积⽹络模型如VGG、GoogLeNet、ResNet等相继出现,⼀次又⼀次地刷新ImageNet⽐赛的榜单。基于这些成功实践的知识和经验,卷积神经⽹络的应⽤范围进⼀步拓展到⽬标检测、语义分割、⼈脸识别等各类计算机视觉任务中。甚⾄在语⾳识别,⾃然语⾔处理等⾮视觉任务中也开始见到卷积神经⽹络的⾝影。
虽然关于深度学习的理论和技术已经取得了长⾜发展,但是其不⾜之处也依然明显。其中较为突出的有计算消耗⼤、容易过拟合、模型可解释性差、不耐对抗攻击等问题。计算和存储消耗问题阻碍了最先进的深度学习算法在如⽆⼈车、⼿机、IoT设备等计算资源有限的设备上的部署。总体来说,深度学习模型⾯临的资源的限制主要来⾃三个⽅⾯:
模型本⾝的⼤⼩。
运⾏时所需要的内存⼤⼩。
模型完成执⾏所需要的计算量。
以被⼴泛使⽤的VGG-16模型为例,该模型有多达1亿千万个可训练参数,如果以单精度浮点型存储这些参数,模型需要占据530MB的存储空间。处理⼀张500×500分辨率的图⽚,需要执⾏近800亿次浮点运算,并且需要460MB额外的内存空间来存储中间的计算结果,这对于低端设备来说是难以承受的负担。2012年以来深度学习⽅法发展如⽕如荼的⼀个重要原因是GPU提供了⽐CPU更多的计算能⼒。但是随着⽹络模型越来越复杂,硬件更新带来的算⼒增长很快就被吞没,模型算⼒需求的增长却没有尽头。模型的精度和计算量有直接关系。越复杂的⽹络模型分类效果越好,但同时也消耗更多的存储和计算资源。降低卷积神经⽹络的计算和存储消耗,是其⼤规模应⽤于实际场景的关键。因此,在模型效果能够基本得到保证的前提下,如何对模型进⾏压缩与加速,受到了学界和⼯业界的⼤量关注。
近年来,越来越多关于⽹络压缩和加速的⽅法被提出,它们从不同的角度去实现⽹络的压缩和加速。⽹络剪枝(network pruning)旨在通过不同粒度去剪除⽹络中的冗余参数;量化利⽤低⽐特数的权重参数来压缩原⽹络;低秩分解(low-rankde composition)主要通过利⽤多个低秩矩阵的外积去近似逼近原权重矩阵来加速⽹络;知识蒸馏(knowledge distilling)通过⼤的教师⽹络去监督⼩的学⽣⽹络学习,达到压缩⽹络的⽬的;紧凑⽹络设计(compactnetwork design)旨在设计轻量、⾼效的⽹络结构,降低⽹络的参数量和计算量。
其中神经⽹络量化在Google发表的《Quantizationand Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference》中建⽴了⼀套更加通⽤的量化标准,并且在tflite中真正实现落地。
量化就是将浮点存储(运算)转换为整型存储(运算)的⼀种模型压缩技术。将原本⽤浮点数表⽰的神经⽹络通过量化,变为⽤定点数表⽰,来减⼩存储空间及运算速率。按照聚类中⼼是否均匀分布,可以把量化分为线性量化和⾮线性量化。
卷积神经⽹络模型的量化⽅法,是直接从数值计算层⾯改变神经⽹络模型的⽅法。这种⽅法通常是作⽤在数值计算中最耗时的部分,浮点数的计算中。这种⽅法对神经⽹络模型的参数值或者激活值进⾏量化,⽐较直观的⼀种是把原来的FP32运算变成FP16或者int18计算。当然,量化后的神经⽹络模型要实现加速,需要有特定设备的⽀持。但是最新的安培系列英伟达GPU已经可以实现FP16和int18的加速。
来⾃MIT的韩松教授《Deep Compression:Compressing Deep Neural Networks with Pruning, Trained Quantization and HuffmanCoding(2016)》就是典型的⾮线性量化,作者使⽤K-MEANS算法对浮点权重进⾏量化,但因需要查表取得原始数据再进⾏计算,所以对计算的加速帮助不⼤,但可以减少模型的存储⼤⼩。

聚类量化的的计算过程
线性量化则通过线性变换,将浮点数通过线性变换转换为定点数,由于神经⽹络对于参数的健壮性,及神经⽹络参数的分布特征,量化后即使有参数精度的损失,在整体计算准确率上损失也不⼤,且可通过量化感知训练QAT(quantization aware training)实现⽹络对于量化损失精度的学习,达到更⾼的准确率。线性量化的应⽤及前景都更为⼴阔,我们接下来将着重介绍两种线性量化⽅法,即后训练量化PTQ(post training quantization)训练后量化(PTQ)(quantization aware training)。

神经⽹络参数分布密度图
训练后量化(PTQ)
算法采⽤预训练的FP32⽹络并将其直接转换为定点⽹络,⽽不需要原始训练。转换⽅法可以是⽆数据的,或者需要⼀个⼩型校准集。因为⼏乎没有涉及到超参数调整、所以可以使它们可以通过单个API调⽤⽤作⿊盒⽅法,这使神经⽹络设计者不必深⼊了解量化神经⽹络,从⽽允许更⼴泛地应⽤神经⽹络量化。PTQ过程中的⼀个重要步骤是为每⼀层找到适合的量化范围。量化通常会有准确性的损失。这也很容易理解。float32本⾝可以存储的取值范围⽐uint8的取值范围要宽,所以不能⽤uint8表⽰,肯定有很多值只能四舍五⼊到uint8。量化模型和全精度模型之间的误差也是由于裁剪舍⼊操作造成的。浮点实数使⽤r,量化定点整数使⽤q。浮点和整数之间的转换公式为:

s是表⽰实数和整数之间的⽐例关系的尺度。z是零点,表⽰量化后实数0对应的整数。计算⽅法如下:

通过这些公式,我们就可以将浮点数映射到⼀个我们已知s和z的整数空间内,对于计算机来说,对于定点数的计算不需要浮点数计算的移位操作,计算速度会提升很多。
PTQ整个过程使⽤定点算法实现。计算完全精度模型后,提前计算每个中⼼特征图的权重、最⼩值和最⼤值,计算尺度和零点,然后将权重量化为int8/ int16整数。整个⽹络量化完成后,就可以按照上⾯的流程进⾏量化推断了。
量化感知训练QAT
训练后量化技术是我们⾸选的量化⽅法。它⾮常有效且实施快速,因为它们不需要使⽤标记数据重新训练⽹络。但是,它们有局限性,尤其是在针对激活的低位量化时,例如4位及以下。后训练技术可能不⾜以减轻低⽐特量化带来的⼤量化误差。在这些情况下。我们可以使⽤量化感知训练(QAT)。QAT在训练期间对量化噪声源进⾏建模。这使得模型能够找到⽐训练后量化更多的最优解。然⽽,更⾼的准确性伴随着神经⽹络训练的通常成本,即更长的训练时间,需要标记数据和超参数搜索。
因为我们在量化的前向传递中使⽤了round即取整函数,round函数的梯度⼏乎处处为0。如果⽹络中存在这个函数,那么反向传播的梯度也将变为0。所以我们可以采⽤直通估计器(Straight Through Estimator)来来近似梯度。卷积层的梯度在伪量化之前直接传回权重。它将round函数的的梯度近似为1,即直接将上⼀层的梯度传到下⼀层。

使⽤STE进⾏量化感知训练的前向和后向计算图
这就是QAT的关键,即使⽤STE处理梯度⽆法计算的问题,从⽽使量化神经⽹络也可以训练,从⽽使模型在训练的过程,学习量化带来的损失,从⽽实现更⾼的准确率。
量化使我们能够从浮点表⽰转变为定点格式,并且与利⽤⾼效定点运算的专⽤硬件相结合,有可能实现显着的功率增益并加速推理。然⽽,为了利⽤这些节省,我们需要能够保持⾼精度的稳健量化⽅法,同时减少权重和激活的位宽。主要介绍了两类量化算法:训练后量化(PTQ)和量化感知训练(QAT)。训练后量化技术采⽤预训练的FP32⽹络并将其转换为定点⽹络,⽽⽆需训练。这使它们成为⼀种轻量级的量化⽅法,⼯程⼯作量和计算成本低。可以在所有⽹络的浮点精度降低的1%内实现权重和激活的8位量化。许多⽹络甚⾄可以量化到4位权重,⽽性能仅略有下降。
量化感知训练通过模拟量化操作对训练期间的量化噪声进⾏建模。与PTQ相⽐,此训练过程可以找到更好的解决⽅案,同时实现更有效和更积极的激活量化。QAT可加⼊批量归⼀化等⽅法,可以实现4位权重量化,与浮点相⽐,准确度仅略有下降。PTQ和QAT之间的选择取决于应⽤的精度和功率要求。这两种⽅法都是神经⽹络量化的重要⽅法。
 Alif Semiconductor发布支持生成式AI的MCU基准测试结果,巩固其在边缘AI领域的领先地位
Alif Semiconductor发布支持生成式AI的MCU基准测试结果,巩固其在边缘AI领域的领先地位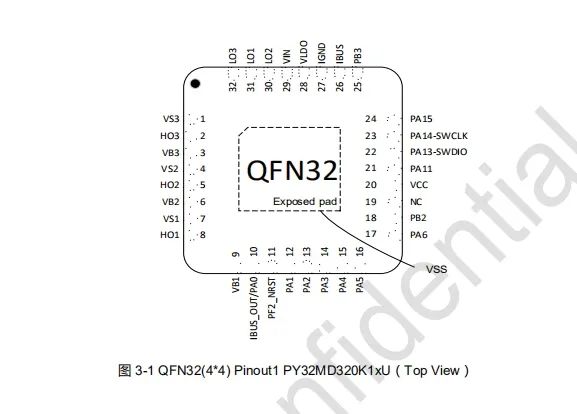 普冉PY32MD320单片机技术规格概述
普冉PY32MD320单片机技术规格概述






 慧聪电子网微信公众号
慧聪电子网微信公众号
 慧聪电子网微信视频号
慧聪电子网微信视频号

精彩评论